Inside the Enclave
Part 1
Footprint’s mission is to bring trust back to the internet, and the first step is building your trust in us. That’s why we believe it’s important to be completely open and build in public. Building in public means sharing how we think about security, system design, and transparency about how we handle sensitive data and the (great) lengths we go to in order to make sure it’s done right. A core part of our strategy here is to lean into a radical new paradigm known as Confidential Computing-- enabling us to process sensitive data in highly-isolated, secure environments that far outpace the typical approaches used by businesses today.
We would first like to start with a simpler question: how do companies protect your data (today)?
There are many answers, but the most common that our team has seen are:
- they don’t (encrypt anything 😱)
- build it in house / use “encryption-at-rest”
- 3rd party tokenization/vaulting services
Many don’t encrypt
While horrifying, this unfortunately isn’t very surprising. Cryptography is hard and in the early days of a business, you simply don’t have many users and therefore not much sensitive data. Encryption and privacy are not the main priorities. Then growth happens, more products and features are added, and before you know it you’re now responsible for heaps of user data that wasn’t built with best practices in mind —it’s even harder to fundamentally fix these problems after the fact.
Encryption at rest
Most modern databases and infrastructures support basic encryption at rest. You can easily enable this in Postgres or MySQL on AWS RDS. This is sometimes called “checkbox security”—it’s a basic protection primarily meant to stop a physical theft of data drives. It means exactly how it sounds: when the data is at rest—meaning not in use—it’s encrypted. If an adversary breaks into the data center and steals the database drive out of the machine, you should be covered! Unfortunately, many businesses treat this as their golden solution to protecting customer data. As we’ve seen time and time again, like the Cisco hack, Twitter hack, and most recent Uber hack, this is simply not effective – as soon as a single point of your "perimeter" is compromised all the encryption-at-rest protections become useless. This is because when a web app backend connects to a database, the data is already decrypted. Any system that has DB access can exfiltrate this data. Most companies expose read access to large numbers of engineers, employees, and support services—it’s an operational necessity in a modern business.
Build it in house
Many engineering teams realize that encryption at rest is simply not enough, and therefore roll their own implementations using a combination of encryption libraries/sdks and services like AWS KMS (key management service).

Unfortunately, encryption doesn’t actually solve any problems, it simply condenses the problem down to the length of a key.
Building key management systems, policies and controls around what systems have access to which keys is a complex problem. Depending on the type of business/product you're building, this is often not the main core competency of your team's product engineers.
Even the use of AWS KMS’s APIs is rather complex: you need to figure out how to properly generate data keys, finding SDKs/libraries to use to encrypt data locally, and then store the encrypted data key along with the encrypted data. Are you properly generating enough random entropy on your systems? Did you use the right parameters for your encryption schemes. Did you properly specify the right policies on who has access to the root keys?
Classic Vaulting Services
It’s not surprising that a handful of companies rose up to address this exact problem. These companies offer a set of APIs (often with SDKs) to completely offload data protection via a REST API.
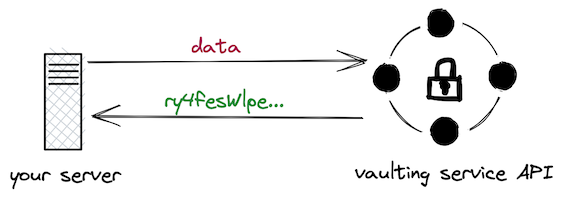
The idea is that you forward your data to a trusted partner that completely takes care of encrypting data and managing the associated keys. For simple use cases, this is a rather simple workflow: (1) ship plaintext data to the vault, (2) get back a “token”, and (3) store the “token” in the database.
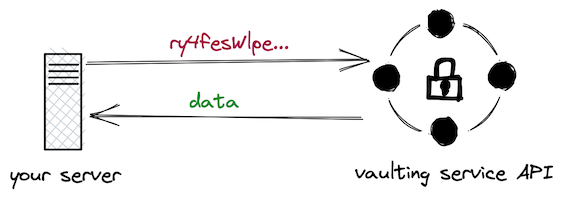
To decrypt, you can simple do the inverse: (1) send the “token” to the API, (2) get back the plaintext, (3) do something with that plaintext.
Vaulting methods: tokenization vs encryption
Tokenization is the process of taking sensitive data, like a credit card number, and turning into a short identifier that references the underlying data but does not reveal its contents. Most vaulting services utilize tokenization as the primary method for data protection. Tokens are usually short strings and therefore easy for businesses store in-place of the original data.
Alternatively, vaulting services could instead return ciphertexts (the resulting encrypted data) and businesses would need to store the encrypted data. In certain cases, this may be preferred as keys are kept separate from the encrypted data. An adversary would need to get access to both in order to get access to the underlying data.
In both cases, classic vaulting services require their customers to store data (a token or a ciphertext) for each piece of data they want to protect. So while you've potentially escaped the complexity around encryption and key management, you still need to store many opaque data identifiers throughout your systems.
This becomes a critical system design decision and it has real consequences for issues like performance and cost. Every data access requires an API call and optimization. It’s usually best to perform bulk operations (and many vaulting services offer encryption/de-tokenization proxies for this exact purpose).
Complexity creeps in
Not all data is created equal. Some fields you may never need to fully decrypt or decrypt a fragment of it (like last four digits of a credit card). Other fields you may actually need to perform searches over, like a birth date or license card expiration. All of these data types may require special design considerations, and all of this adds complexity which you usually need to reason about on day 1. Classic vaulting services typically support APIs to specify field types to handle common cases. These are the typical system design decisions businesses need to make when integrating vaulting services into their stack. Unfortunately, these design decisions add extra complexity and still don’t even cover all the use cases businesses may need over time.
Costly lock in
Classic vaulting services can be prohibitively expensive depending on your usage. They often discourage usage by charging heavily for each access/decryption. This may not be a problem in the initial integration, but this pricing strategy forces a lock-in and makes it difficult to migrate to newer, perhaps more sophisticated, technologies. This is critical system design decision to consider: what use cases might you have now (or in the future) that could change how frequently you’ll need to send of decryption/de-tokenizing requests?
Does not compute
One of the main problems with classic vaulting is that it usually fails to achieve our goals of confidential computing: once you decrypt some underlying sensitive data where do you compute functions on it? Many businesses still need perform basic computations in non-secure environments, thereby weakening their overall posture on data protection.
Advanced cryptographic techniques like Fully Homomorphic Encryption are still in active research, not yet sufficiently performant enough, and would still require complex key management and systems security hardening that most businesses would likely need to offload anyways.
A new hope: confidential computing
In the last decade, many hardware infrastructure companies have been hard at work designing the primitives that make up today's landscape of confidential computing. Companies like Intel who built SGX, Apple with their Secure Enclave, and Google’s Titan chip have laid the foundation for building truly isolated computing and key management systems to protect users' confidentiality and privacy at its core.
Until recently, technologies on the cloud/server side have been somewhat lacking the same kinds of guarantees of isolation we get on personal computing devices. Famously, Signal — arguably one of the world’s most private messenger apps — wrote about their use of server-side use of SGX in practice. However, even SGX has problems: it has been repeatedly broken by security researchers and many question whether it’s a feasible technology to deploy at scale. Furthermore, SGX is not wildly available on clouds like GCP or AWS which makes it much harder to deploy in practice.
In the last couple of years, a new entrant has emerged in one of the most popular cloud companies: Nitro Enclaves are a capability from AWS on select EC2 machines that provide isolated compute environments that are designed for processing highly sensitive data. They provide CPU and Memory isolation and massively reduce the attack surface area when used correctly.
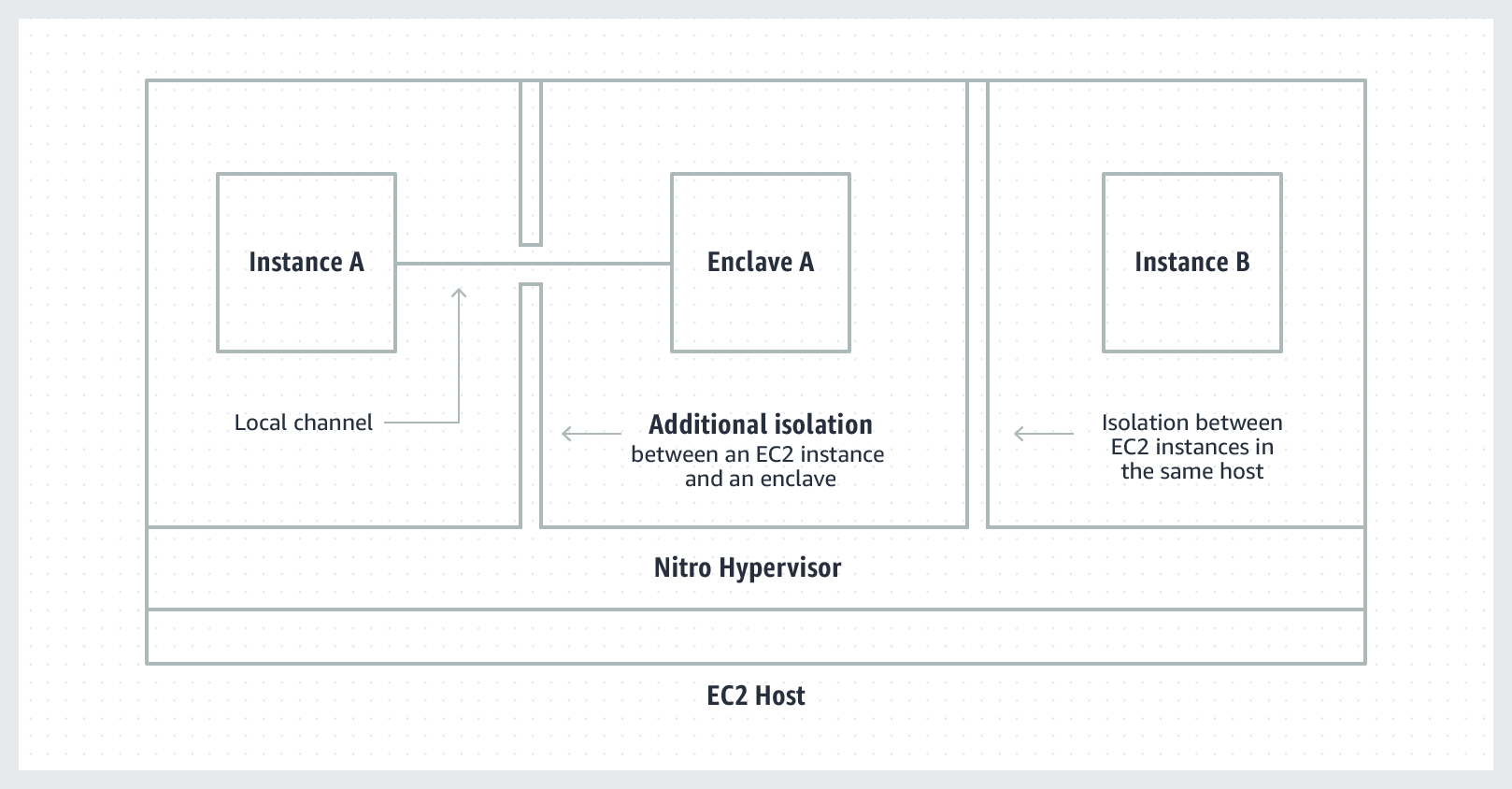
Nitro Enclaves are architected with several key security features:
- Fully isolated & hardened VMs: no persistent storage, no interactive access, no external networking, even root users on machine cannot access, nitro hypervisor for memory/cpu isolation
- Hardware-level cryptographic Attestation: prove the enclave’s identity and verify that it is running authorized code
- Integrates with AWS Key Management Service (KMS): use KMS to generate a key pair whose private key is ONLY accessible inside the enclave
Note: AWS is not the only player in the space. Google Cloud offers their own Confidential Computing environments powered by AMD SEV. More on this in a future post!
Inside the (Nitro) enclave
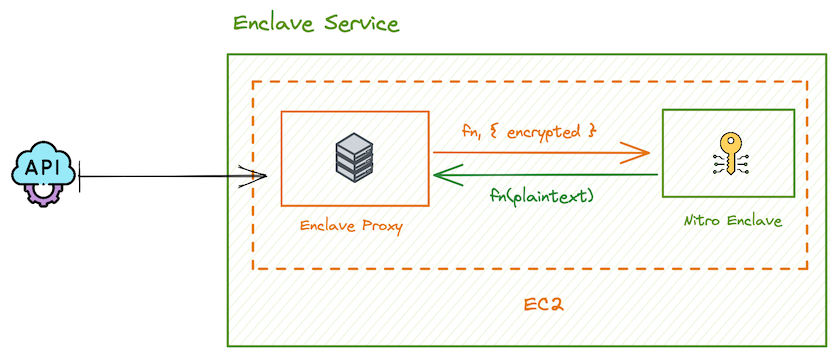
Next in the series, we’ll cover a number of topics like:
- the inner workings of Nitro Enclaves, and how they compare to similar technologies like AMD SEV and SGX.
- our exclusive use of Rust on the backend and in the enclave
- our extensible RPCs and how we (privately) compute functions inside the enclave
- our approach to fine-grained Access Control and attribute-level Audit Logging
- users’ ownership over their enclave-powered vaults
- single-token semantics for verifying identity and vaulting PII
- building a unified API for vaulting and KYC
We’ll jump into the nitty gritty world of Nitro Enclaves, how Footprint leverages this amazing new technology, and how our approach builds on the shoulders of giants so you don’t have to.
